LLMs can dream of electric sheep, but can they add?
February 16, 2024
Contents
I've used GPT4-Turbo for all these experiments since it is the most capable model, and I have a bunch of credits.

It's perplexing to me how an LLM model can produce "sparks of AGI" and yet not be able to add two integers, given that they are sufficiently large.
The size shouldn't matter. After all, "123 + 356" follows the same algorithm as "1391378213910318931139038713813891398131" + "1381376138139137130232112321". GPT4 knows this quite well:
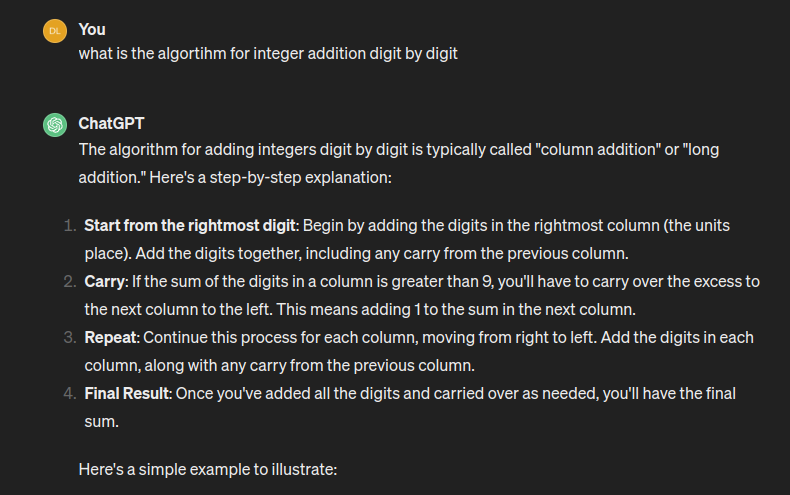
It "knows" exactly what to do yet can't actually do it consistently all the time. Computers are very good at following instructions precisely every time, so in a sense, this is human-like behavior.
Ok, but why? Why can't it do it?
Let's think about what an LLM model is actually doing.
Given a list of previous tokens, it predicts the next token. That's it.
In the case of integer addition, the LLM has to know the answer before it begins to write it down.
Integer addition is even more interesting in this regard because the result of the first 4000 digits doesn't necessarily have any impact on the next 8. If the carry is 0, it's effectively a clean slate. But this gives the illusion that the LLM actually knows what it's doing much more than it does.
We can show it can add any combination of 1, 2, and 3-digit pairings perfectly. Below are results from generating random numbers of a certain length. "addition_experiment_100_2_3.csv" refers to 2 digits for the first number and 3 digits for the second number. The code for these experiments are here.
CODE BLOCKpython3 main.py 100 2 3
CODE BLOCK"addition_experiment_100_2_3.csv": 1.0, "addition_experiment_100_2_5.csv": 1.0, "addition_experiment_100_1_3.csv": 1.0, "addition_experiment_100_3_1.csv": 1.0, "addition_experiment_100_3_2.csv": 1.0, "addition_experiment_100_3_3.csv": 1.0,
And so, given the first 3 digits of each number, it will generate a possible output, in the worst case being off by -/+ 1 number in each digit output.
But it has no idea what the previous carry was!
We can see this quite clearly if we increase the size to 15 digits:
CODE BLOCKAdding 528216453043329 and 470786533633379 Incorrect output. Got: 998002986676708 Expected: 999002986676708 Top Logprobs 0, Chosen Token = '998' ... logprobs: ['998' - 98.55,'999' - 1.45,' ' - 0.0] 1, Chosen Token = '002' ... logprobs: ['002' - 93.78,'003' - 6.09,'902' - 0.03] 2, Chosen Token = '986' ... logprobs: ['986' - 100.0,'9' - 0.0,'987' - 0.0] 3, Chosen Token = '676' ... logprobs: ['676' - 100.0,'677' - 0.0,'6' - 0.0] 4, Chosen Token = '708' ... logprobs: ['708' - 100.0,'698' - 0.0,'707' - 0.0]
It chose "998" instead of "999". But picking "999" would require knowing there was a carry. The likelihood of such an error increases the larger the number.
If it did know the carry, it could accurately predict the output digit and next carry.
CODE BLOCKpython3 single_digit_carry.py
CODE BLOCK"digits_accuracy": 1.0, "carry_accuracy": 1.0
So, given digits 9 and 4, the output would be "3 1".
So the LLM knows exactly what to do and can do every step, but it still can't do it. It's a fundamental limitation of its stateless, autoregressive nature.
Interestingly, we can get it to do long addition perfectly by creating a loop where we feed in 1 digit from each number at a time and maintain a state of the current carry and whether or not there is a next digit. The LLM is called at each step in the loop.
We can also use a scratchpad approach, although this fares worse than the prior one, since it becomes lazy after a while. Not to mention, it doesn't take less time.
CODE BLOCKpython3 scratchpad.py 1 64 64 Adding 9298624807126040090200132098542375567688220045413316567661402521 and 7288223821868003141594376421811294404283553659154968481348341915 CompletionUsage(completion_tokens=667, prompt_tokens=370, total_tokens=1037) Scratchpad output: Let's calculate the sum digit by digit from right to left, keeping track of the carry. ### Scratchpad: - Current Output Digit: - Carry: Starting from the rightmost digit: 1. 1 + 5 = 6, Carry = 0 2. 2 + 1 = 3, Carry = 0 3. 5 + 9 = 14, Output Digit = 4, Carry = 1 4. 2 + 4 + 1 (carry) = 7, Carry = 0 5. 0 + 3 = 3, Carry = 0 6. 4 + 8 = 12, Output Digit = 2, Carry = 1 7. 1 + 4 + 1 (carry) = 6, Carry = 0 8. 3 + 6 = 9, Carry = 0 9. 3 + 9 = 12, Output Digit = 2, Carry = 1 10. 5 + 5 + 1 (carry) = 11, Output Digit = 1, Carry = 1 11. 4 + 1 + 1 (carry) = 6, Carry = 0 12. 4 + 5 = 9, Carry = 0 13. 0 + 3 = 3, Carry = 0 14. 0 + 5 = 5, Carry = 0 15. 2 + 6 = 8, Carry = 0 16. 0 + 5 = 5, Carry = 0 17. 0 + 5 = 5, Carry = 0 18. 0 + 8 = 8, Carry = 0 19. 9 + 4 = 13, Output Digit = 3, Carry = 1 20. 0 + 0 + 1 (carry) = 1, Carry = 0 21. 4 + 1 = 5, Carry = 0 22. 6 + 3 = 9, Carry = 0 23. 0 + 0 = 0, Carry = 0 24. 2 + 2 = 4, Carry = 0 25. 6 + 8 = 14, Output Digit = 4, Carry = 1 26. 4 + 8 + 1 (carry) = 13, Output Digit = 3, Carry = 1 27. 8 + 2 + 1 (carry) = 11, Output Digit = 1, Carry = 1
Results for long addition:
CODE BLOCKpython3 long_addition.py 64 ... Adding digit 64 - 7 and 6 with carry 1, end=True ChatCompletion(id='chatcmpl-8sxgj1dz6dlII2hKsTVinSkP6EImx', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='14', role='assistant', function_call=None, tool_calls=None))], created=1708109845, model='gpt-4-0125-preview', object='chat.completion', system_fingerprint='fp_f084bcfc79', usage=CompletionUsage(completion_tokens=1, prompt_tokens=262, total_tokens=263)) Got: 14, 14 and carry 0 Total elapsed time: 71.21612238883972 seconds Num1: 7315675594010421095929703857350974671480590181705735114505202830 Num2: 6986542108280062145149689090455484783661043278682743688399383004 Output: 14302217702290483241079392947806459455141633460388478802904585834 Expected: 14302217702290483241079392947806459455141633460388478802904585834, Correct: True
Long addition in this fashion works for arbitrary sized digits, although it might take a really, really long time.
Needle In A Haystack
The LLM has to find a needle in a haystack using the scratchpad approach. Given the prompt, it has to identify the current digit and carry. The Gemini paper shows that this is possible even in the context of 1 million tokens.
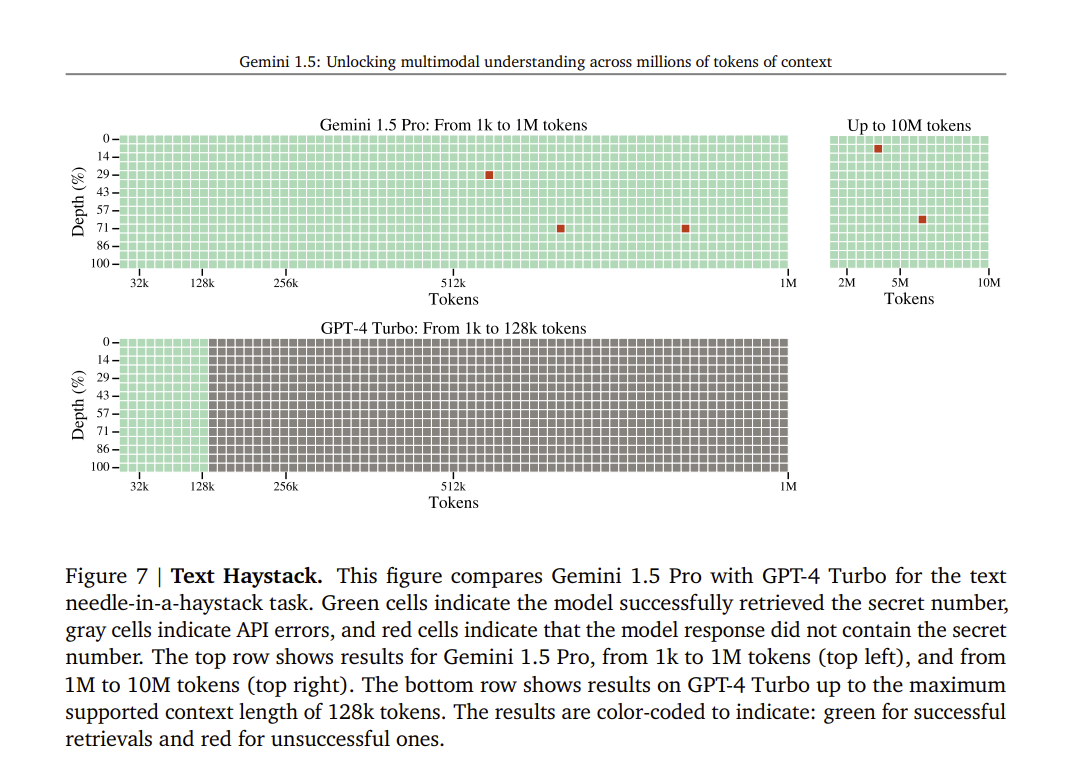
Putting this all together, if the prompt has all the information related to the carry for each digit, then the LLM should be able to output the correct result with very high certainty.
Speculative Thoughts
I'm becoming more and more convinced that LLMs in their current incarnation are not "thinking of new things" but rather outputting the most probable thing based on all the context. It's like a generative search engine, or what might have been originally envisioned for Google. I find it increasingly unlikely that if you took GPT4 (5, 6, etc.) back in time before Einstein figured out general relativity, it would have figured it out itself. This does not mean novel solutions are out of reach. Rather, they need to be navigable from the current search space. And through RLHF, new data can be added. For example, GPT cutoff dates have become more and more recent. But can it create a completely new space of thought entirely? Can it create new physics? My bet would be no. And tangentially, what if it overfits the "things we know dataset"?
In deep learning, the phenomenon of "double descent" arises whereby standard metrics indicate the model is overfitting; the training loss keeps going down while the test loss goes up. Not good. Then, all of a sudden, the test loss starts to go down, seemingly miraculously. So, given a large enough model and an even larger dataset, it turns out you can press the train button and things will work. I'm obviously hand-waving like crazy here, but that's kind of how it is.
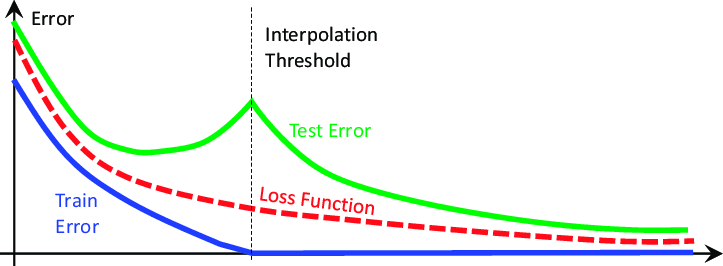
Now, what if it is trained on the entire internet, a.k.a. everything? Do we even care about overfitting? Is it even bad anymore? From a purely academic point of view, I suppose it is, but you have a model that can tell you anything you want to know about everything you want to know. Would you even care?
Perhaps this is nonsensical reasoning in the first place. If almost every problem we have is solvable within the current search space, then it ceases to matter and becomes more of an intellectual circle-jerking exercise. "Oh, it solved climate change, cancer, and renewable energy, but it can't do new physics, so is it really AGI?"
The goal post is moved once again.
Experiment Notes
- Initially, I thought that the LLM favoring 3-digit tokens was a significant problem and that using 1-digit tokens would improve accuracy. You can increase the likelihood of choosing single-digit tokens by adjusting the
logit_biasparameter. However, you need to increase it substantially to have any noticeable impact. Additionally, you have to increase the end-of-text (EOT) token by a similar amount; otherwise, the model will get stuck in a loop untilmax_tokensis reached. Interestingly, this adjustment did not have the intended effect. The model would output 1 or 2 single-digit tokens and then stop. I believe this is because the training data for the LLM includes single-digit tokens before stopping the numeric output. Otherwise, there would be no reason to use 2- or 3-digit tokens. I also attempted a negative bias on all 2- and 3-digit tokens, but the maximum size of the bias map is 300, making it infeasible. - Sometimes, the LLM outputs nonsensical output. I believe this is a systematic error. I have encountered this issue multiple times with other language models. You can have a perfectly normal prompt, and then the model will go off on a tangent that has nothing to do with it. It is possible that this is due to how inference is performed on OpenAI's end. I wouldn't find it hard to believe that they use machine learning models to determine if the input prompt has been "answered" before and then output the result of that.
- The LLM performs much better at addition when the number of digits on the left-hand side (LHS) is greater than or equal to the number of digits on the right-hand side (RHS). I believe the reason for this lies in the fact that when we do addition, we generally put the larger number first (think of grade school). Perhaps the training set examples are biased towards this scenario.